
Generative Kanji
In this article, we build a text-to-image AI that learns Chinese characters in the same way humans do - by understanding what their components mean. It can then invent new characters based on the meaning of an English prompt.

prompt for the word "queen" over 80,000 train steps.
Other Links
- Associated Code github repo
- Basic Intuition Behind Stable Diffusion
Table of Contents
Introduction
Japanese Kanji characters not only carries phonetic info, but they also carry simple semantic meanings. The kanji 净 (ジョウ) consists of the radical 氵 (water) and the phonetic component 争 (ソウ). And, the radical 氵 associates the character with the semantic field of water, liquid, or purification, while the component 争 provides the phonetic cue.
I’ve long been curious about applying machine learning to the study of Kanji characters. Could an algorithm learn their structure purely from images and meanings? And if so, might it even be capable of creating entirely new characters? (Short answer: it can.)
Goal
The first step is question what defines a well generated novek Kanji? To me, A well-generated novel kanji is one that fuses two or more radicals in a configuration that has not existed historically, while still following the structural logic of Kanji. Each radical remains visually distinct, while their combination conveys the integrated meaning of the given English prompt. For instance, suppose the kanji “休” never existed, but combining two radicals “亻” and “木”, based on the prompt “person tree” is considered a well generated novel kanji.
Technique
My overall approach will be fine tuning with Lora on a Stable Diffusion v1.4.
Dataset
Describe the dataset?
The dataset contains 1,600 Kanji images, comprising 16 distinct radicals with 100 character samples per radical. For each image, the resolution is 128x128 and caption with one or multiple short english phases.
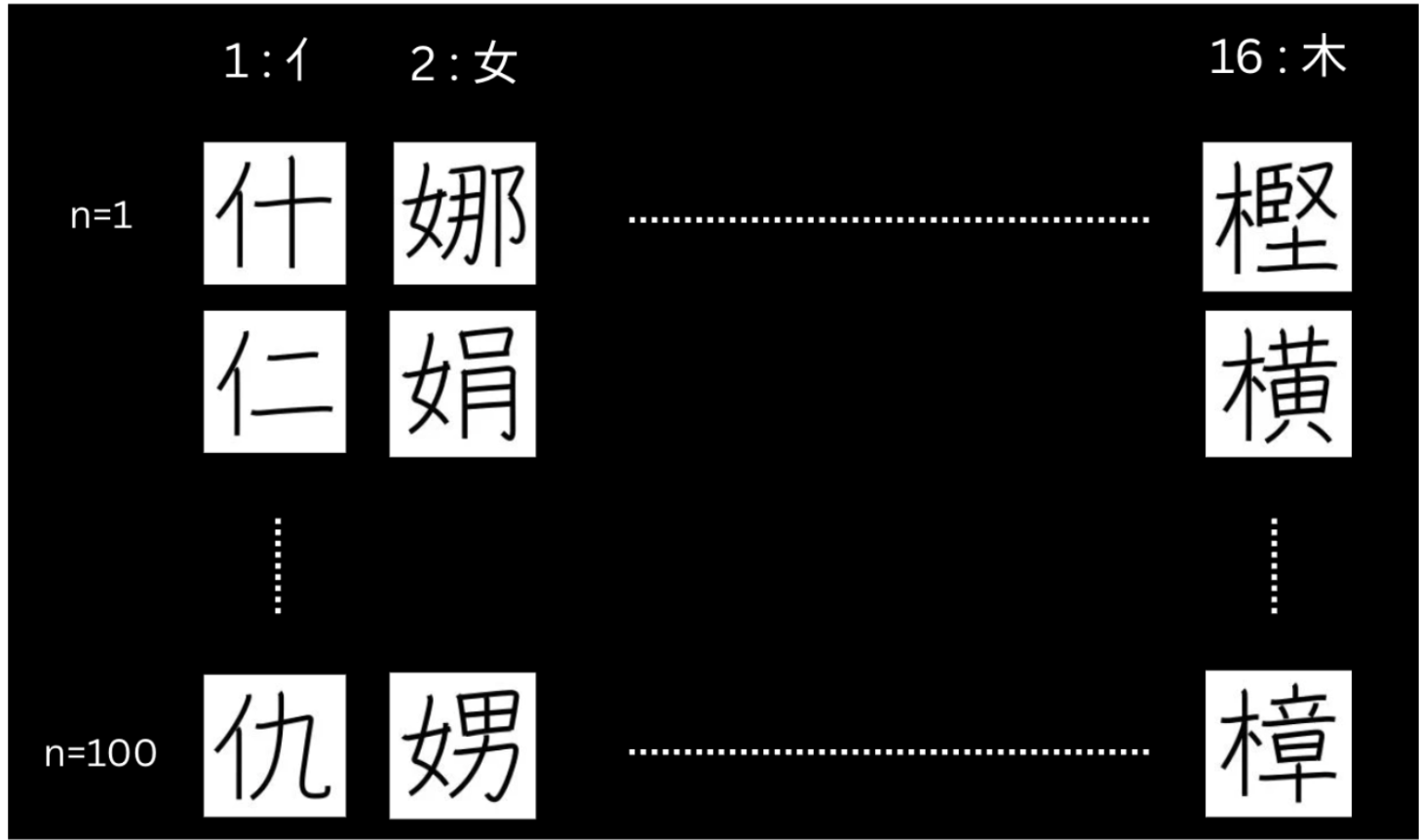
Why this Dataset?
Using an unbalanced number of radicals in Kanji can skew a model’s preference for certain radicals over others. For example, if 90% of the training data includes kanji with the radical “亻”, the model will likely generate responses that heavily feature this radical. In contrast, using a balanced number of radicals in Kanji ensures each radical has equal likelihood to be represented in the model’s output. This balance allows the model to learn a more accurate mapping between text prompts and visual features.
In addition, I also selectively choose those 16 distinct radicals. These radicals are selected because they commonly appear on the left side of the character structure. When most main radicals appear on the left of a kanji (equivalent to say latent images having shared features) , it gives a smooth interpolation in the latent space. This smooth interpolation allows sampling at inference to be more coherent, which eventually makes kanji generation more meaningful. For instance, a latent space with “林” & “他” will have a smoother interpolation compared to “林” & “草”, as the former radicals “木” and “亻” are both positioned on left side, while latter radicals “木” and “艹” are positioned on left and top.
Procedure
What’s the overall procedure?
Overall, I’ve used stable diffusion v1.4 as the base model and Lora as the fine tuning technique. I only fine tune on the U-Net’s cross attention weights. A single RTX A5000 GPU was used for training. These are parameters used during the training :
- Rank = 64
- Batch size = 1
- Number of epoch = 8
- Learning rate = 1e-04
- Learning rate scheduler = cosine
Training Choice
Why Higher Rank in Lora?
Higher-ranking models capture a more nuanced mapping between text and images. For example, they can distinguish and map “休” and “林” to “human tree” and “tree-tree” compared to lower-ranking models. This is because higher-ranking models can adjust more portions of the attention weights, which determines the strength of semantic conditioning and influences the nuance mapping. In other words, higher rank allows cross attention to reshape the latent distribution with greater semantic nuance.
Why a batch size of 1?
One batch size is chosen because each kanji has fine grained unique stroke details. Multiple batch sizes average out the gradients across different kanji’s, which wash out the subtle detail of strokes. Eventually, most of the output kanji will look similar.
Why is a high number of Epochs required?
A high number of epochs is required because Kanji generation depends on subtle spatial differences. Repeated training refines denoising, not only aiming for accuracy at global level strokes, but also low level strokes. In contrast, I hypothesize that a low number of epochs mostly results in distorted images with high number stores due to lack of refinement in low level strokes.
Why set the learning rate as cosine?
Cosine is chosen because training requires a strategic staged process: early on, cross-attention weights must shift quickly toward Kanji-like latent space from the generic image latent space. And later, the weights must shift slowly within the kanji-like latent space to learn the subtle differences in the stroke. In contrast, if we set the learning rate as constant, it will take a longer time to first shift the denoising path towards the Kanji-like region in the latent space. As a result, the denoising model (U-net) spends its time outside the Kanji-like region. In addition, if the learning rate is not reduced when the model is denoising within the kanji-like region, the model will not be able to adjust small-fine grain strokes. In other words, a high learning rate pushes the model’s weights heavily, so the model’s denoising trajectory shifts more abruptly.
Results
The results are as expected. We see each glyph is uniformly biased towards a specific radical. Additionally, semantic meaning between the used radicals and prompted text is well aligned. For instance, the radical “金” is used for prompts : “Nintendo Switch”, “Gundam”, “One Axe”, “Crown Box”, and this makes sense as these prompts are related to the idea of metallic. It excels at prompt with basic phrases such as “Ring” or “Axe”, but struggles at pronouns such as Elon Musk. In conclusion, having a large data size with even numbers of radicals appear in different position of image, and having multiple phrases in caption to ensure wide range of semantic coverage (or prepare enough kanji that fills and smooth the semantic space to be compact) is the key to generate a novel kanji successfully.

English phrases with non trivial meaning

English phrases used in training sets

English phrases that 16 dinstinct radicals meaning