
Solar Panel Code Refactoring AI Agent
Solar Panel Diagnostics Web Application
Problem
Our client is a software company that helps diagnose the health of solar panels. In the past, they diagnosed solar panel health on a per-customer basis, but now they want to build a website so anyone can use it. However, the existing code is a single 10k-line MATLAB file, while the website requires a modularized Python codebase. On top of that, the code involves complex scientific calculations, so ensuring correctness is critical.
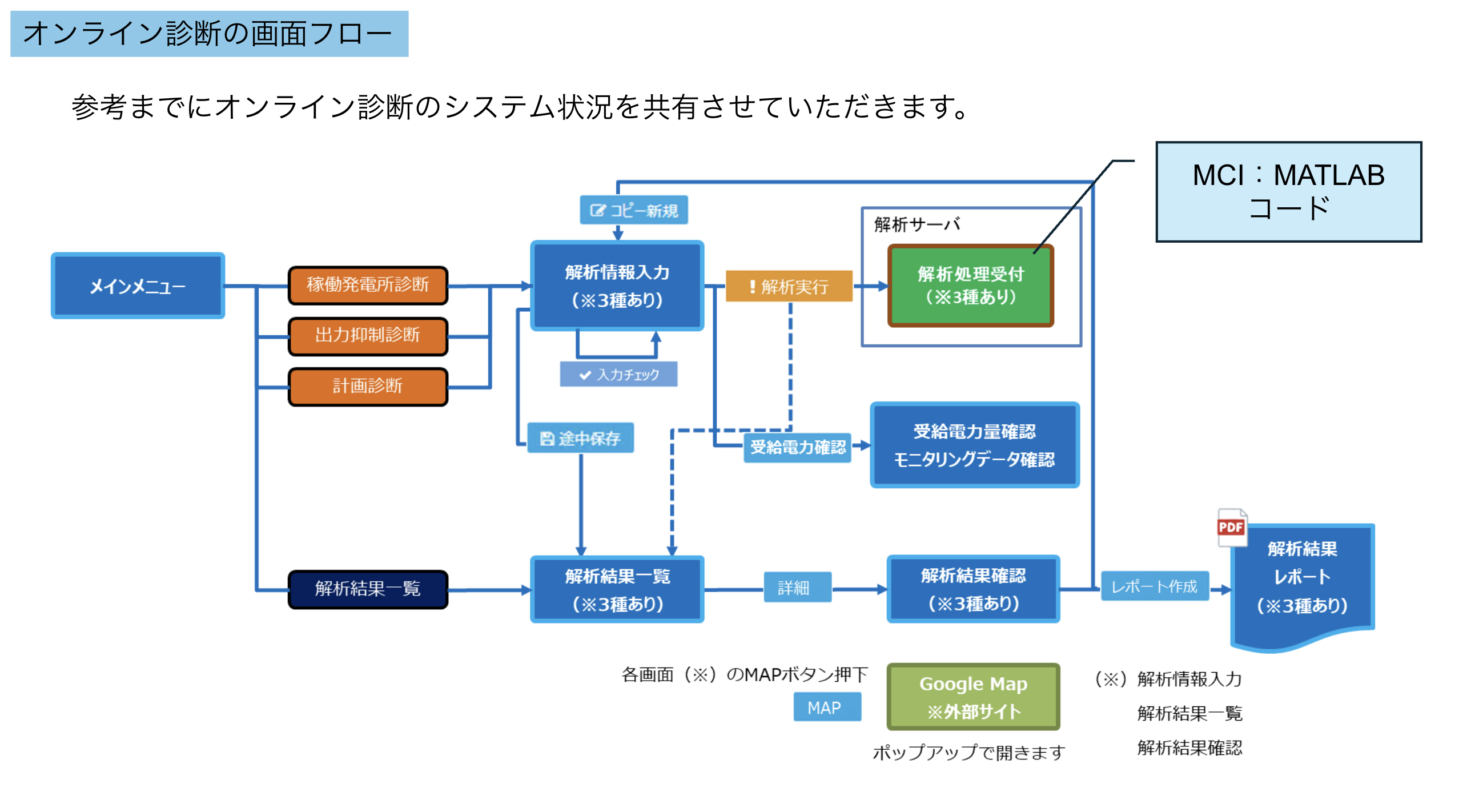
Ideal architecture for the web application
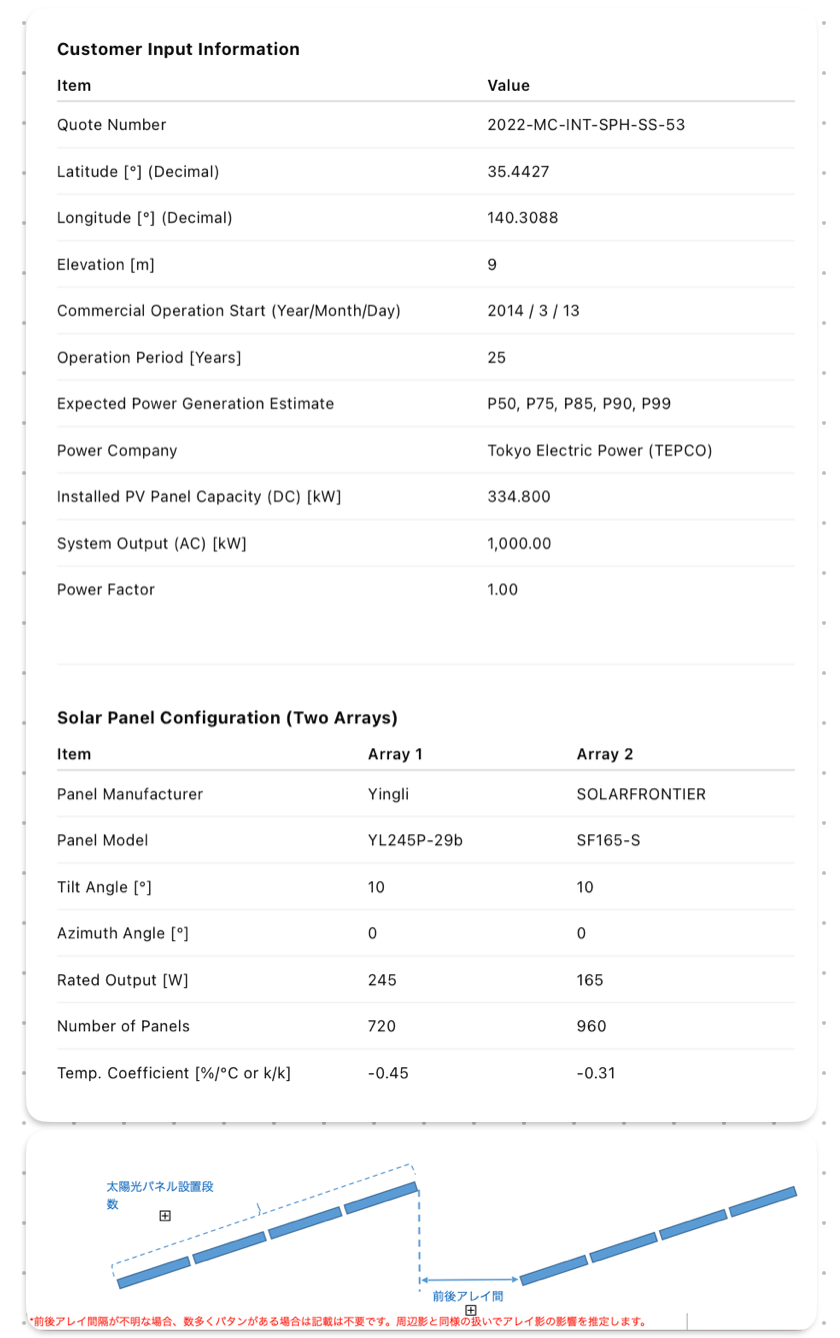
Understanding the input data
The goal of the web application is to take a solar panel configuration, hourly weather data, and actual power generation as inputs, and output the theoretical power generation. By comparing the theoretical and actual power generation, the system can calculate the lost generation and provide insights into solar panel health. Here, we show some sample input data :
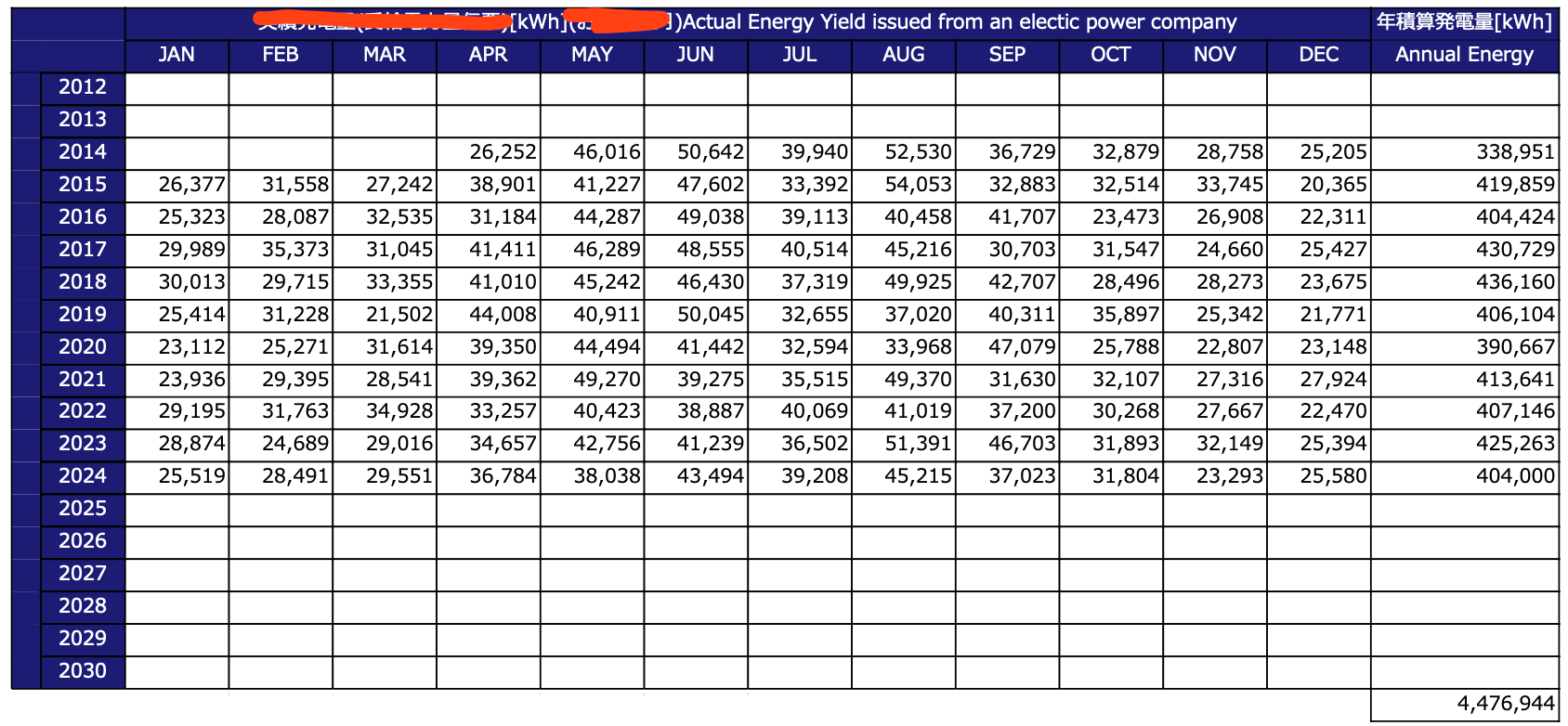

Solution
We aim to build an AI agent that modularizes the legacy code end to end. Given a part of the legacy code, a predefined module structure, and past client data, the agent:
- Generates a 6-file Python module referencing the legacy code and structure
- Creates input values by inspecting the module
- Produces corresponding outputs from the module and inputs
- Runs tests in a containerized Docker environment
- Generates a PDF report of the results
Key Challenges
These are the key challenges during the development :
- Legacy code have no documentation
- LLM struggle at multi file integration
- Retrieving relevant parts of legacy code
- Difficult to validate the accuracy of scientific computation
Here, we briefly explain how we solved these challenges.
[1] A long range LLM was used to propose the optimal structure.
[2] We define the high-level structure of a single module and ask the LLM to write a main entry point with function signatures for multiple classes. By ensuring that inputs and outputs across classes are consistent, the entire module remains coherent, and when the LLM fills in the specifics, there is no confusion.
[3] Ingesting the full legacy code into a vector database confused the LLM due to complexity. Instead, we removed the code but kept comments, which provide high-level context without noise. This allowed the LLM to use comment pairs to identify relevant code chunks more effectively.
[4] This is the toughest challenge: validating the correctness of Agent-generated scientific code. For example, given an array of solar panels and the sun’s position, the code computes the shading factor to adjust power generation. To verify correctness, we need not only input/output test cases but also intermediate values. Since no archived intermediates exist, we allow the Agent to generate them.